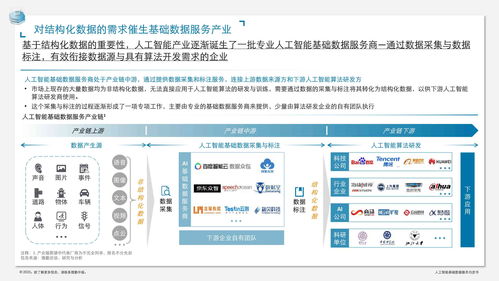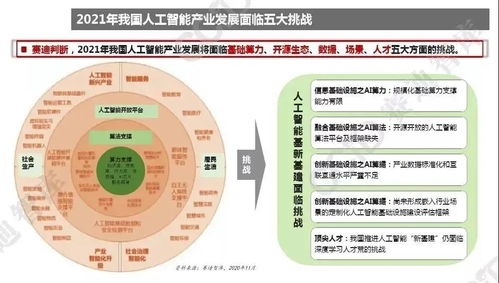
2021年,中国人工智能产业在经历了数年的高速增长后,进入了一个更加注重基础能力与长期价值的新阶段。其中,作为驱动整个AI技术栈的“灵魂”,人工智能基础软件的发展尤为关键,呈现出几个鲜明且重要的趋势。
趋势一:开源生态成为技术发展与协作的核心驱动力
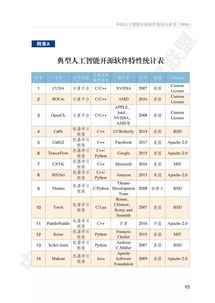
2021年,中国AI基础软件领域对开源模式的拥抱达到了前所未有的高度。以百度飞桨(PaddlePaddle)、华为MindSpore、一流科技OneFlow等为代表的国产深度学习框架,通过积极建设和运营开源社区,极大地降低了AI开发与部署的门槛。开源不仅加速了技术迭代与创新,更促进了产学研用各方的深度融合,形成了良性的技术共享与反馈循环。企业通过开源策略,能够快速构建开发者生态,确立技术标准,从而在激烈的市场竞争中占据有利位置。
趋势二:从“技术导向”到“场景融合”,强调工程化与易用性
随着AI技术从实验室走向千行百业,基础软件的发展重点从单纯的追求算法性能峰值,转向如何更高效、更稳定地服务于具体业务场景。因此,2021年的AI基础软件平台普遍强化了其工程化能力,包括:
- 模型开发与部署的全流程支持:提供从数据标注、模型训练、自动调参到模型压缩、端边云一体化部署的完整工具链,追求“一站式”体验。
- 降低使用门槛:通过自动化机器学习(AutoML)、低代码/无代码开发平台等工具,让业务专家和非专业算法工程师也能参与AI应用构建。
- 与行业知识深度融合:基础软件平台开始提供更多面向金融、工业、医疗等垂直领域的预训练模型、组件和解决方案,加速行业AI落地。
趋势三:自主可控与软硬件协同创新进入深水区
在复杂的国际技术环境下,构建自主可控的AI技术体系成为国家战略与产业共识。2021年,这一趋势在基础软件层体现为:
- 国产AI框架与国产AI芯片的深度适配与优化:各大框架均加强了对华为昇腾、寒武纪等国产AI芯片的专门优化,致力于打通从底层算力到上层应用的国产化全栈能力,提升整体性能与效率。
- 基础软件内核的自主创新:在编译器、运行时、算子库等底层核心技术上进行持续投入,减少对国外开源项目的核心依赖,提升系统的安全性与可控性。
趋势四:大规模预训练模型催生基础软件新范式
受GPT-3等巨型模型的启发,2021年中国在超大规模预训练模型领域取得突破性进展(如北京智源研究院的“悟道”、百度的文心ERNIE系列)。这对基础软件提出了新的要求:
- 超大模型的分布式训练能力:需要基础软件能够高效支持千亿乃至万亿参数模型在数千张GPU/芯片上的稳定、高效训练。
- 模型即服务(MaaS)的普及:基础软件平台开始将强大的预训练模型以云服务API或小型化工具的形式提供,使开发者能够基于这些“基础模型”进行微调和二次开发,极大提升了AI能力的普惠性。
趋势五:重视安全、可信与治理
随着AI应用日益深入社会经济生活,其安全性、公平性、可解释性等问题备受关注。2021年,相关的治理要求开始传导至基础软件层。AI开发平台逐步集成模型鲁棒性测试、公平性检测、可解释性分析以及数据隐私保护(如联邦学习支持)等工具,帮助开发者构建“负责任的人工智能”。
****
总而言之,2021年中国人工智能基础软件产业正走向成熟,其发展路径清晰地表明:未来的竞争不仅是算法与模型的竞争,更是生态、工程化体系、软硬件协同以及治理能力的综合竞争。一个更加开放、务实、自主且负责任的基础软件生态,正为中国的数字化转型和智能化升级构筑坚实底座。